The following guide is for ubuntu 16.04 LTS with Apache Spark 2.3.0.
Important
First, update all of the OS packages.
apt-get update apt-get upgrade
- Download from Apache the latest version of spark with hadoop precompiled.
Download Spark-2.3.0-bin-hadoop2.7.tgz from http://spark.apache.org/downloads.html Java should already be installed on your ubuntu OS, but you will need scala:
apt-get install scala tar xvzf spark-2.3.0-bin-hadoop2.7.tgz mv spark-2.3.0-bin-hadoop2.7 /usr/local/spark
Add to ~/.bashrc , so that the binaries can be found in the PATH env.
export SPARK_HOME=/usr/local/spark export PATH=$SPARK_HOME/bin:$PATH
- Source .bashrc to load it up, or just re-login.
To start the spark scala shell with the hadoop-aws plugin, run the following:
spark-shell --packages org.apache.hadoop:hadoop-aws:2.7.5
You will then see the following:
Using Scala version 2.11.8 (OpenJDK 64-Bit Server VM, Java 1.8.0_162) Type in expressions to have them evaluated. Type :help for more information. scala>
- Using the Content UI, create a domain such as "
s3.demo.example.local" and a bucket called "sparktest". - Open the
sparktestbucket and upload a test text file calledcastor_license.txt. Create an S3 token for this domain and pass it to spark, as follows:
scala> sc.hadoopConfiguration.set("fs.s3a.access.key", "2d980ac1fabda441d1b15472620cb9c0") scala> sc.hadoopConfiguration.set("fs.s3a.secret.key", "caringo") scala> sc.hadoopConfiguration.set("fs.s3a.connection.ssl.enabled", "false") scala> sc.hadoopConfiguration.set("fs.s3a.path.style.access", "true") scala> sc.hadoopConfiguration.set("fs.s3a.endpoint", "http://s3.demo.example.local")To test, run a command to read a file from Swarm via S3 and count the words inside it:
scala> sc.textFile("s3a://sparktest/castor_license.txt").count() res5: Long = 39Note
s3a URI syntax is
s3a://<BUCKET>/<FOLDER>/<FILE>ors3a://<BUCKET>/<FILE>These three commands apply the wordcount application against the text file in s3 and sends back the results of the reduce operation to s3.
scala> val sonnets = sc.textFile("s3a://sparktest/castor_license.txt") sonnets: org.apache.spark.rdd.RDD[String] = s3a://sparktest/castor_license.txt MapPartitionsRDD[3] at textFile at <console>:24 scala> val counts = sonnets.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _) counts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[6] at reduceByKey at <console>:25 scala> counts.saveAsTextFile("s3a://sparktest/output.txt")Browse to see the Spark UI jobs and stages:
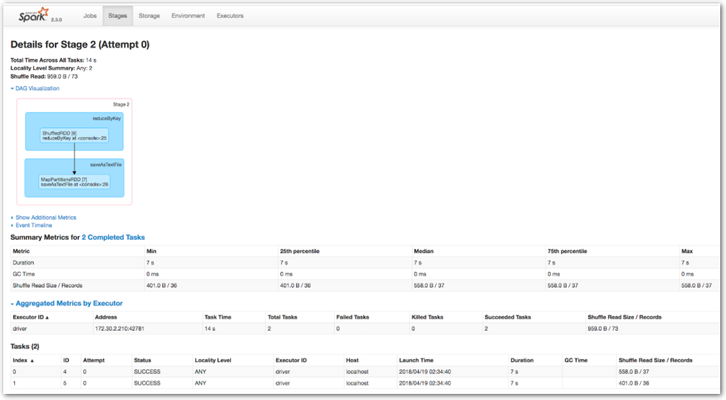
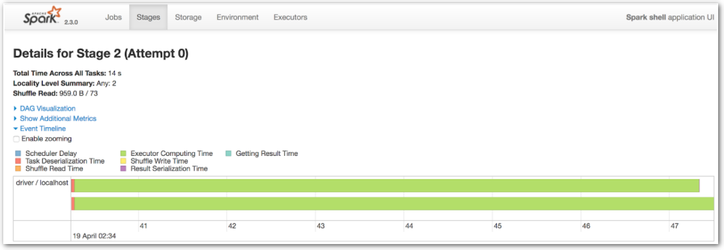
http://<IP>:4040/jobs/ http://<IP>:4040/stages/stage/?id=2&attempt=0
It also works with SSL (even self-signed certificates):
scala> sc.hadoopConfiguration.set("fs.s3a.connection.ssl.enabled", "true"); scala> sc.hadoopConfiguration.set("fs.s3a.endpoint", "https://s3.demo.sales.local") scala> sc.textFile("s3a://sparktest/castor_license.txt").count() res8: Long = 39
Spark Web UI Examples