...
Swarm Hybrid Cloud provides the capability to copy objects from Swarm to a target, such as S3 or Azure cloud storage destination. Native cloud services and/or applications running on utility computing can computing work with data directly from the target cloud storage. Future releases provide additional capabilitiesSimilarly, use either S3 or Azure to pull data from cloud storage to Swarm.
Capabilities
The Content UI provides access to the capabilities.
It functions with the The remote storage can be AWS S3 object storage service and supports or general S3 buckets as the target cloud . Content Portal 7.7 and later additionally supports Azure blob storage.
It The feature uses the provided target remote bucket with an S3-valid name, endpoint, access key, and secret key, or the remote Azure container account and key or SAS URL.
It The feature uses a selected dataset to copy to or from the cloud (known as the ‘focus dataset’). This can be a bucket/container, a folder within the bucket/container, or a dynamic set of criteria from a collection of the Swarm source.
The focus dataset remains in the native format in the target cloud storage, and users. Users/applications/servicesread the focus dataset directly in the target cloud storage without any additional steps.
The integrity of all objects in the focus dataset is preserved as it is copied to the target cloud storage. Status is provided with the result of each copy from the focus dataset for reference and verification.
The object metadata can be preserved, modified, or removed in part depending on the target storage systemobject’s modification time and content type are preserved. All other objects' metadata are not preserved during the copy. The target storage system may add new metadata on incoming objects.
Objects are transferred securely.
The initial current release enables the requires that the focus dataset transfer to be initiated on a manual basis.
| Info |
|---|
Info Each object from the focus dataset is copied is copied to or from the cloud and does not move to or from the cloud. They remain within The objects remain on the source for user discretion. Each object remains on the Swarm namespace as the authoritative copy and remain remains searchable in the Swarm namespace after the copy. The object’s data is processed on the cloud and can be repatriated to Swarm with Content Portal 7.7 and later, if desired. |
The “folder” path of each object is preserved.
The payload size and hash integrity are checked at the target cloud storage and reported in the log file.
The target bucket may exist already. If not, create a target bucket or container using the provided known credentials. Either way, target credentials need permission for bucket or container creation. This functionality may change in future releases.
Objects with Unicode in the name are supported.
Future releases will provide additional capabilities.
Prerequisites
Gateway is version 7.10 or later. (7.8 supports minimal copy to S3 cloud functionality)
Content Portal User Interface is version 7.7 or later. (7.5 supports minimal copy to S3 cloud functionality)
Docker Community Edition is installed and must be started on the Gateway server(s).
See https://docs.docker.com/config/daemon/systemd/?msclkid=36e68349c0d411ecb438f130e19228bc for starting a Docker, and https://docs.docker.com/engine/install/linux-postinstall/#configure-docker-to-start-on-boot for setting up Docker to start on the server restart.A bucket with focus dataset to copy is created on Swarm UIis defined. This may be an entire bucket, a folder within a bucket, or a collection that is scoped to content within a single bucket.
A bucket or container is created on the target remote cloud storage service.Both token ID and S3 secret key are generated on the target cloud storage
serviceKeys or credentials are available for the remote cloud storage.
Usage
Swarm Hybrid Cloud feature is accessible to clients via Content UI. Clients need to select a specific dataset to copy to the cloud, which can be either a collection, a bucket, or a folder within a bucket. Provide the target remote bucket or container details, e.g., endpoint, access key & secret key, etc. Results for each object are provided in the source bucket as a status file. The focus dataset is defined shortly after the job is triggered and is not redefined during execution. Use the generated dictionary and log files to review the job.
...
Hybrid Cloud helps in replicating the focus dataset, therefore, the client needs two environments:
Swarm Content UI
Target Remote cloud storage service
Copy all the data from the source location (Swarm) path, or subset of the source path defined by a focus dataset, to the destination (client’s target cloud storage service). It is applied at the bucket level . The entire data residing in a bucket can be copied and then placed at the destination. This whole process of replicating data needs job creation at the source locationjob creation is initiated from a Swarm bucket-scoped view.
Create a job at the bucket level to start copying the focus dataset to the target cloud storage service.
Irrespective of Whether or not the focus dataset was copied successfully or not, there are two or more files created after the job submission:
Manifest File - Contains information such as total object count & size, endpoint, target bucket name, access key, and secret key of focus dataset copied.
Dictionary File(s) - Contains the list of all focus datasets copied if the focus dataset is defined from the Swarm side. The dictionary file displays the name of each object along with the size in bytes. Note that these are not generated when an entire bucket or folder is being copied to the cloud.
Log File - Provides a run summary or error message and contains the current status of each object of the focus dataset copied, along with details from the final check. The log file is generated after the objects are queued up to copy and, is refreshed within every two minutes. There are four potential statuses for each object:
Pending - An initial state where the object is queued up for the copy.
Failed - When an object is failed to copy to the target cloud storage service. Reasons include the target endpoint is not accessible, or any issue with an individual object, such as too large object name for S3. See the Gateway server log for failure details if not specified within the log file.
Copied - When an object is successfully copied.
Skipped - When an object is skipped. Reasons include the object already exists at the destination, the object does not exist at the source, or the object is marked for deletion and cannot be copied.
Result Summary - Provided with Content Portal 7.7 and later. The result summary appears in JSON format after job completion, with a link to the log file.
Each file is important and provides information about the focus dataset copied from the Swarm UI to the target cloud storage servicehybrid cloud job. The format of these may change in future releases. The Manifest and Log files are overwritten if the same job name is used from a previous run, so save the files or use a different job name if this is not desired.
| Info |
|---|
If required, renaming of a single or all support files is possible after the copying has started. Any log file updates continue under the old name. |
...
Navigate to the Swarm UI bucket or collection to copy.
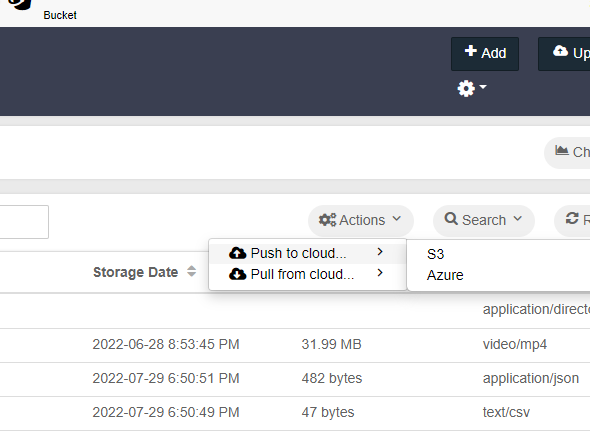
Click Actions (three gear iconsgears icon) and select either “Push to cloud” or “Pull from cloud” (formerly Copy to S3). Select S3 or Azure depending on the remote endpoint. A modal presents a form, with required fields marked with asterisks (*) as shown in the example below:

.png?version=1&modificationDate=1643299918421&cacheVersion=1&api=v2)
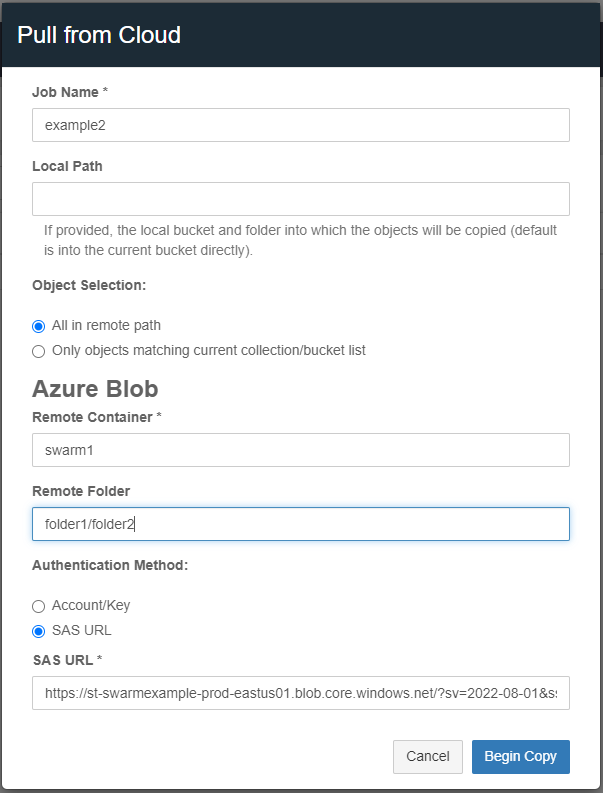
Job Name - Provide a unique name for the job. The manifest and log files are overwritten if a job name is reused from a previous run.
Local Path - Provide the bucket name and any optional subfolders. Objects are copied directly to the bucket if the field is left blank. This is an option when pulling from the cloud.
Object Selection - An option when pulling from the cloud.
All in the remote path - Select this option to copy all the objects/files from the remote location.
Only objects matching the current collection/bucket list - Select this option as a filter to repatriate and update only the objects/files that already exist in the Swarm destination to the remote version.
S3End Point
Endpoint - A
remote service endpoint.
For AWS S3
endpoints - The format is shown in the screenshot above.
For Swarm
endpoints - The value needs to be in the following format with HTTP or HTTPS as needed:
https://
{DOMAIN}:
{S3_PORT}
Region - The S3 region to use. Some S3 providers may not require region.
Remote Bucket - Enter the
remote bucket name.
Remote Folder - An optional folder path within the remote bucket.
Access Key - An access key for the
remote bucket and must be generated within the
remote cloud storage service.
Secret Key - An S3 secret key. It is generated with the access key.
Azure Blob
Remote Container - Enter the Azure container name.
Remote Folder - An optional folder path within the remote container.
Authentication method can be Account and Key, or SAS URL.
The SAS URL needs permission to list in addition to other relevant file permissions.
Click Begin Copy. This button is enabled once all required text fields are filled.
The copy operation generates the earlier support objects (manifest, dictionary object, log, and logresult). All objects use the given job name as a prefix but are appended with separate suffixes. The duration of the job depends on the size of the job (the count of objects and the total number of bytes to be transferred). Download and open the latest copy of the status log to monitor the status of the job.
...
Some errors may display after successful request initiation while the errors that do not display in the page details or , status log file, or in the result summary, are detailed in the Gateway log. Verify the endpoint and access keys are correct and not expired.
| Child pages (Children Display) |
|---|